
 实验4:SPSS数据频数分析、多选项分析
返回
实验4:SPSS数据频数分析、多选项分析
返回
一、实验名称和性质
所属课程 | 社会科学SPSS统计分析软件 |
实验名称 | SPSS数据频数分析、多选项分析 |
实验学时 | 6 |
实验性质 | 验证 |
必做/选做 | 必做 |
二、实验目的
掌握数据文件在SPSS基本页面操作
三、实验的软硬件要求
硬件环境要求:
IBM兼容机;奔腾2.0GHz以上CPU;1GB内存以上;CD-ROM光驱(用来安装);
10GB硬盘空间
使用的软件名称、版本号以及模块:
SPSS20.0所有模块
四、知识准备
前期要求掌握的知识:
了解计算机基本知识,会使用windows操作系统。
实验相关理论或原理:无
五、实验材料和原始数据:详见随书附带光盘资料。
六、实验要求和注意事项:按照相关的操作流程逐一操作,不要漏掉某些关键指标。
二、实验内容
样本数据采集到后,不能立即用于数据分析,在进行数据分析前,需要首先了解一下样本数据的基本特征。
1.样本描述(了解数据的基本特征)
样本数据采集到后,常用一些统计量描述原始数据的集中程度和离散状况,对数据的总体特征进行归纳。
Spss中的Analyze菜单中的“Discriptive Statistics”下面的子菜单进行样本数据的描述。
(1)频数分析过程
使用student.sav做例子
通过菜单项“Analyze”|“Discriptive Statistics”|“Frequencies…”,打开如图1所示对话框
该过程通过数据频数分析来达到整理数据的目的,利用该过程,得到一系列描述数据分布状况的统计量





 图1
图1
 对图1做简单的解释
对图1做简单的解释
①Variable(s):对此列表框中的变量进行频数分析
②Display frequency tables:若选中,将在输出窗口中显示频数分析表
③Statistics…按钮:单击该按钮,打开“Frequencies:Statistics”对话框,如图2,



![]()

图2
该对话框中各选项的意义如下:
![]() Percentile Values方框:选择方框内的选项,计算并显示分位数
Percentile Values方框:选择方框内的选项,计算并显示分位数
² Quariles:计算并显示四分位数
² Cut points:在后面的窗口输入数值,假设为p(p为2至100之间的整数),则计算并显示p分位数
² Percentile(s):在后面的窗口中输入数值(0到100),可以有选择的显示百分位数。
![]() Central Tendency方框:选择该方框内的选项,计算并显示描述中心趋势的统计量
Central Tendency方框:选择该方框内的选项,计算并显示描述中心趋势的统计量
² Mean:计算并显示样本数据的均值
² Median:计算并显示样本数据的中值
² Mode:计算并显示众数
² Sum:计算并显示数据的累加和
² Values are group midpoints复选框:假设数据已经分组,而且数据取值为初始分组的中点,选择此项,计算百分位数统计和数据的中位数。
![]() Dispersion方框:选择方框内的选项,计算并显示描述数据离散趋势的统计量
Dispersion方框:选择方框内的选项,计算并显示描述数据离散趋势的统计量
² Std.deviation:标准差
² Variance:方差
² Range:极差
² Minimum:样本数据的最小值
² Maximum:样本数据的最大值
² S.E.mean:均值的标准误差
![]() Distribution方框:设置描述数据分布的统计量
Distribution方框:设置描述数据分布的统计量
² Skewness:显示样本数据的偏度和偏度的标准误差
² Kurtosis:显示样本数据的峰度和峰度的标准误差
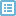
④Charts按钮:单击此按钮,打开“Frequencies:Charts”对话框,如图3,

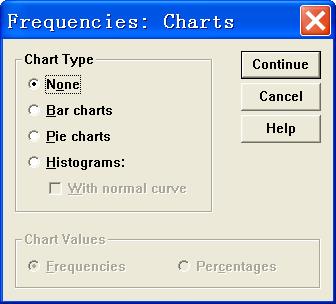
图3
该对话框内各选项的意义如下:
² None:默认,选择此项,不生成和显示图形
² Bar chart(s):生成和显示条形图
² Pie chart(s):生成和显示饼图
² Histogram(s):生成和显示直方图
² With normal curve:选择Histogram(s)后,此复选框变为可用。选择此项,在生成和输出直方图时添加正态曲线。
⑤Chart Values方框:在“Chart Type”方框内选择“Bar charts”单选钮和“Pie charts”单选钮后,该方框中的选项变为可用。通过此项的选择,确定生成图形时条形(相对于条形图)的长度或扇区(对于饼图)面积的度量。
² Frequencies:为默认选项,用分类变量不同取值对应的个案数做为度量
² Percentage:用分类变量不同取值对应个案数占总个案数的百分数做为度量。
⑥Format…按钮:单击该按钮,打开“Frequencies:Format”对话框,如图4所示。利用该对话框,设置频数分析表的输出格式。


图4
(2)数据描述过程
该过程可以计算单变量的描述统计量,如可以计算商店顾客的平均收入,可以查看围绕这个平均值变换的范围有多大或计算高于或低于平均值的某个范围内有多少观测值。
该过程主要计算描述集中趋势和离散趋势的各种统计量,并可对变量进行标准化处理
使用student.sav
通过菜单项“Analyze”|“Discriptive Statistics”|“Descriptives…”,打开如图5所示的对话框。



图5
Variable(s)列表框:对此列表框中所有变量的数据的分布特征进行描述
Save standardized values as variables:选择该项,对“Variable(s)”列表框中的当前变量的数据进行标准化,然后将标准化后的数据保存到一个变量中,变量名为原变量的变量名前面添加字母“z”。新生成的变量和数据保存到当前数据文件中并显示在数据编辑器的最后一列。
Options按钮:单击该按钮,打开“Descriptives:Options”对话框,如图6所示
![]()

图6
其中Display Order方框:该方框内的选项设置描述表格中数据的显示顺序。别的选项跟前面的图2中的各项意义相同
2.数据列表与报表输出
采集到的数据往往都是随机的、杂乱无章的,无法一下从中看出什么规律来,对原始数据进行列表整理,可以使数据更易于阅读、检查。
(1)OLAP Cubes(在线分析处理)过程。用于按给定的范围对一个或多个变量做出描述,可以得到一些常用的描述统计量,其特点是可以分层变化不同水平的组合进行变量的描述。
(2)Case Summaries(个案简明统计报表)过程。对记录进行汇总,与OLAP Cubes过程相比,它的功能要强大的多,不仅可以计算描述统计量,还可以分组进行汇总,并能够给出详细的记录列表。
(3)Report Summaries in Rows/Columns(行列形式报表)过程。这两个过程的功能相似,不过是分别按行和列输出结果。和Case Summaries过程相比,这两个功能显然又进了一步,它们均可以对输出表格进行精细定义,以满足客户的各种苛刻要求。
(1)OLAP Cubes(分层报表过程)
分层报表过程对分类变量的不同取值对应的统计量分别建立报表。
注意:在结果窗口中输出的OLAP结果最初给出分析变量全部观察单位的基本统计量,若要显示某一分层的结果,可通过在线交互方式实现。在线交互操作的方法:在选定的表格上双击,然后在表格的左上角会显示分层变量,通过对变量的不同水平的选择,表格中会相应的显示基本统计量,这一过程是在线交互的
使用Test.sav
通过菜单项“Analyze”|“Reports”|“OLAP Cubes…”,打开如图7所示对话框。




图7
下面简单的介绍图7中各选项的意义
①Summary Variable(s):在该列表框中输入变量名,对应变量做为综述变量。
②Grouping Variable(s):在该列表框中输入变量名,对应变量做为分组变量。
③Statistics…按钮:单击此按钮,打开如图8所示对话框。在图8对话框中设置选项,确定需要计算和显示的统计量。右边的窗口就是需要计算的统计量。

图8
各统计量的意义如下:
Sum:数据累加和
Mean:算术平均值
Percent of Total Sum:某类数据的总和占全部数据总和的百分数
Percent of Total N:某类数据对应的个案数占总个案数的百分数。
Median:中值
First:第一个数
Variance:方差
Std.Error ofKurtosis:峰值的标准误差
Std.Error of Skewness:偏度的标准误差
Geometric Mean:几何平均值
Percent of Sum in:各综述变量对应的某分类变量的数据之和占总数据总和的百分数
Percent of N in:各综述变量对应的某分类变量的数据对应的个案数占总个案数的百分数
Grouped Median:组中值
Minimum:最小值
Range:极差
Last:最后一个数
Kurtosis:峰度
Skewness:偏度
Harmonic Mean:调和平均值
④Title…按钮:单击此按钮打开对话框,用于在此对话框中输入分层报表的标题和注释内容
(2)个案列表过程
通过此,可以对原始数据中各个个案的数据进行整理
特点:将数据编辑窗口中的全部或部分源数据在结果窗口中罗列出来,以便浏览或打印,同时可对数据的基本特征进行描述
使用Test.sav
通过菜单项“Analyze”|“Reports”|“Case Summaries…”,打开如图9所示对话框。
![]()
![]()
![]()




图9
下面对图9对话框中的各选项意义描述如下:
①Variable(s)列表框:确定对哪些变量的个案数据列表
②Grouping列表框:其中的变量为分组变量
③Display Cases:选中此项,将在列表中显示全部的单个个案对应的统计量,否则只显示各分组对应的统计量。
④Limit cases to:选择此项,在后面的窗口中输入数值,确定最多在列表中显示多少个个案。
⑤Show only valid cases:选择此项,只显示有效数据对应的个案
⑥Show case numbers:选择此项,显示个案号
⑦Statistics…按钮:单击此按钮,打开图10所示对话框,跟图8相似

图10
⑧Option按钮:单击此按钮,打开如图11所示的对话框

图11
图11中,各选项的意义如下
Title:列表的标题
Caption:列表的注释信息
Subheading for totals:选择此项,将在表中显示分组变量不同
Exclude cases with missing values listwise:选择此项,剔除含有缺失值的个案
Missing statistics appear:在该窗口中输入字符、字母或短语,用于标注缺失的统计(当有效个案太少时,有的统计过程将不执行)
(3)行综述报表
特点:行综述报表可罗列原始数据,其格式是以观察单位为行标题,以报告变量为列标题,与个案列表过程相比,可给出更为复杂的报告形式,其输出格式的设置也更为详细
使用constitution.sav
通过菜单项“Analyze”|“Reports”|“Report Summaries in Rows… ”,打开如图12所示对话框。

![]()


![]()



| 窗口中有不少对格式进行设置的选项,也可以在报表在输出窗口生成后在输出窗口中进行修改 |

图12
图12中各选项的意义如下:
①Data Columns:在该列表框中输入变量名,然后单击“Format”按钮,打开如图13所示对话框。在该对话框中进行设置,确定列表框中变量的输出格式。
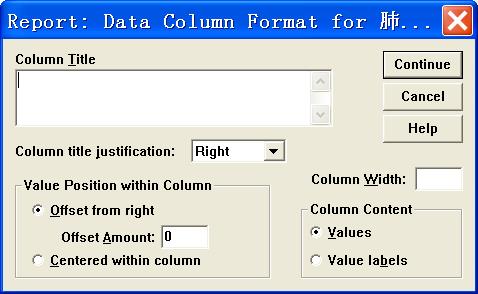
图13
图13中各选项的意义如下:
² Column Title列表框:在该列表框中输入变量的列标题。不输入,则输出变量标签或变量名
² Column title justification下拉列表框:确定列标题的对齐方式
² Value Position within Column:确定变量值在列中的位置
² Column Width:在该窗口中输入数值,确定列的宽度。如果不设置列宽,则系统自动进行设置
² Column Content:确定列中输出的内容
②Break Columns:在方框内的列表框中输入变量名,对应变量做为分组变量。其它选项的设置如下:
Ø Sort Sequence方框:
Ø Ascending单选钮:选择此项,输出时对分组变量及其统计量做升序排列
Ø Descending单选钮:选择此项,输出时对分组变量及其统计量做降序排列
Ø Data are already sorted:选择此项,表示数据文件中的数据已经进行了排序,不必再进行排序(运行该过程时,系统自动进行排序)
Ø Summary按钮:单击此按钮,打开如图14所示对话框。该对话框用于确定对当前选择的分组变量的数据计算什么描述统计量

图14
对图14中的选项说明如下:
² Percentage above:选择此项,在后面的Value窗口中输入数值,计算并显示当前统计量中大于该数值的数据的个数占数据总个数的百分数。
² Percentage blow:选择此项,在后面的Value窗口中输入数值,计算并显示当前统计量中晓于该数值的数据的个数占数据总个数的百分数
² Percentage inside:选择此项,在后面的Low窗口和High窗口中分别输入下限和上限,计算并显示当前统计量中界于上限和下限之间的数据的个数占数据总个数的百分数。
Ø Options按钮:打开如图15所示对话框

图15
图15中各选项的意义说明如下:
² Skip lines before单选钮:选择此项,在各分组变量对应的输出数据之间设置空行。默认值为1,最多可以设置20行空行
² Begin next page单选钮:选择此项,各分组变量对应的输出数据分不同的页面显示
² Begin new page & reset page number:选择此项,下一个分组变量对应的数据在新的一页中输出,并且按顺序编排页码
² Blank Lines before Summaries:在该窗口中输入正整数N(N<21),将在分组标签与该统计量之间插入N行空行。默认值为0
Format按钮:打开如图16所示对话框

图16
③Preview复选框:选择此项,显示报表输出预览
④Display Cases复选框:选择此项,对每个个案的数据或者变量的值标签输出报表
⑤Report方框:该方框内提供了4个按钮,单击不同的按钮,打开不同的对话框,进行设置,对报表做更多的定义。
² Summary按钮:在打开的对话框中设置描述统计量
² Options按钮:打开如图17所示对话框,对缺失值等的表示进行设置

图17
² Layout按钮:在打开的对话框中确定报表的页面输出格式
² Titles方框:在打开的对话框中确定报表标题和脚注。
(4)列综述报表
使用constitution.sav
通过菜单项“Analyze”|“Reports”|“Report Summaries in Columns… ”,打开如图18所示对话框。

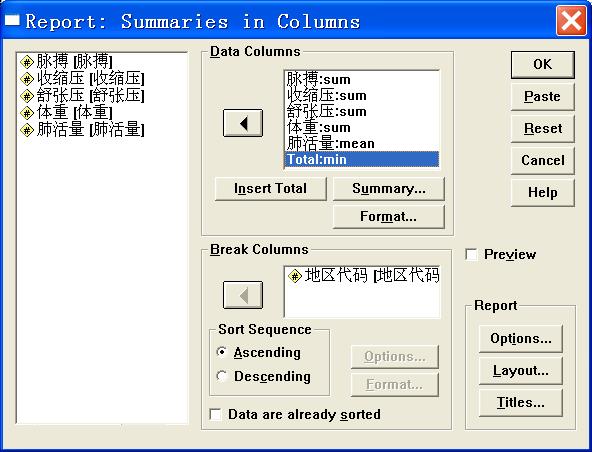

![]()
![]()

 图18
图18
①Data Columns方框:在该方框内的列表框中输入一个或多个变量名,然后利用该方框内的其它选项进行更多的设置
² Insert Total按钮:单击该按钮,给列表框中当前选中的变量名对应的变量数据添加求和统计量
² Summary按钮:单击该按钮,根据列表框中当前选项的不同,打开不同的对话框。如果当前选项为变量名,在打开如图19所示对话框,具体设置见前。如果列表框中的当前选项为求和统计量,则打开如图20所示对话框,在该对话框中确定对所选择的变量名对应的变量数据进行某种运算,作为当前求和统计量的取值。

图19

图20
² Format按钮:打开的对话框中设置变量数据统计量的输出格式
②Break Columns方框:在方框内的列表框中输入变量名,对应变量作为分组变量。利用方框内的选项和按钮,进行更多的设置。
Option按钮:打开如图21所示对话框

图21
③Preview复选框:选择此项,确定进行报表预览
④Report方框:单击方框内的不同按钮打开不同的对话框,对报表做更多的设置
八、实验结果和总结
实验结果以打印的实验报告为准。理解测验报告,总结实验过程,完成实验报告。
九、实验成绩评价标准
本实验采用五级评分制
A:能够熟练掌握软件,正确导出测评报告;实验报告内容完整、书写规范,能正确理解实验结果;
B:能够熟练掌握软件,正确导出测评报告;实验报告内容完整、书写比较规范,基本理解实验结果;
C:能够熟练掌握软件,正确导出测评报告;实验报告内容基本完整、书写基本规范,基本理解实验结果;
D:能够掌握软件,正确导出测评报告;实验报告内容基本完整、书写规范性较差,不能完全理解实验;
E:不能够掌握软件,不能正确导出测评报告;实验报告内容不完整、书写不规范,不能正确理解实验结果;