
 实验10:SPSS中的聚类分析
返回
实验10:SPSS中的聚类分析
返回
一、实验名称和性质
所属课程 | 社会科学SPSS统计分析软件 |
实验名称 | SPSS中的聚类分析 |
实验学时 | 4 |
实验性质 | 验证 |
必做/选做 | 必做 |
二、实验目的
掌握数据文件在SPSS的建立与管理
三、实验的软硬件要求
硬件环境要求:
IBM兼容机;奔腾2.0GHz以上CPU;1GB内存以上;CD-ROM光驱(用来安装);
10GB硬盘空间
使用的软件名称、版本号以及模块:
SPSS20.0所有模块
四、知识准备
前期要求掌握的知识:
了解计算机基本知识,会使用windows操作系统。
实验相关理论或原理:无
五、实验材料和原始数据:详见随书附带光盘资料。
六、实验要求和注意事项:按照相关的操作流程逐一操作,不要漏掉某些关键指标。
七、实验步骤及内容:1.SPSS中时间序列分析简要介绍
依时间顺序排列起来的一系列观测值称为时间序列,跟大部分的统计不同,这类资料的先后顺序是不能忽视的,更关键的是观测值之间不独立。因此,这类数据不能用普通的统计方法解决。时间序列分析(Time series)是专门用于分析这种时间序列资料的统计模型。它考虑的不是变量之间的因果关系,而是重点考察变量在时间方面的发展变化规律,并为之建立数学模型。
时间序列分析的方法可以分为两大类:Time domain和Frequency domain。前者将时间序列看成是过去一些点的函数,或者认为序列具有时间系统变化的趋势,它可以用不多的参数来加以描述,或者说可以通过差分、周期等还原成随机序列。后者则认为时间序列是由数个正弦波成分叠加而成,当序列的确来自一些周期函数集合时,该方法特别有用。不同的专业领域习惯用不同的方法:经济学习惯用Time domain,而电力工程专家则对Frequency domain更感兴趣。下面讲述的都是Time domain
由于时间序列模型的复杂性,它在spss中横跨了数据整理、统计分析和绘图三大部分,具体来说是:
² 预处理模块:包括用于填充序列缺失值的Transform | replace Missing Values过程,建立时间变量的Data | Define dates过程和将序列平稳化的Transform | Create Time Series过程。
² 图形化观察/分析:时间序列在分析中高度依赖图形。Spss为其提供了特有的观察工具:序列图(Sequence Chart)、自相关/偏自相关图(Autocorrelation Function,ACF & Autocorrelation Function,PACF)、交叉相关图(Crosscorrelation Function,CCF)、周期图(Periodogram)和谱密度图(Spectral Chart)。后三者被统一放置在Graphs | Time Series菜单中。
² 分析模块:它们被统一放置在Analysis | Time Series菜单中,共包括指数平滑法(Exponential Smoothing过程)、自回归线性模型(Autoregressive model)、ARIMA模型和季节解构(Seasonal Decomposition)四种方法。
2.时间序列的建立和平稳化
在对数据拟合时间序列模型前需要进行一系列的准备工作,首先,如果数据存在缺失值的话就要进行填补;第二,SPSS是不会自动将数据文件识别为时间序列的,必须要加以定义;第三,原始的时间序列往往要经过初步的计算(平稳化)才能更好的用于进一步分析。
2.1缺失值的填补-Replace Missing Values过程
大多数时间序列模型都要求数据序列完整无缺,但这实际上非常难以做到。当序列中存在缺失值时,显然不可能采用剔除的方法,因为这样会使得缺失值之后数据的周期发生错位。在这种情况下就应当使用Replay Missing Values过程对缺失值采用适当的方法进行填充,并将结果存入一个新变量。
例子:打开数据文件gnp.sav,删除变量gnp在第8、14条记录中的数值,然后选择适当的缺失值填充方法对其进行填充。
缺失值填充方法有好几种,但各有使用范围,现在gnp序列的规律并不清楚,为保险起见,我们只利用缺失值附近的数据进行填充。
方法:Transform | Replace Missing Values
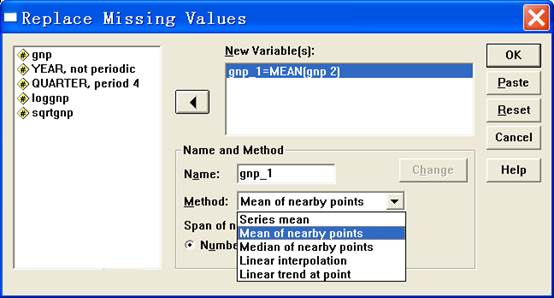
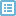
图1
图1中解释如下:
New Variable框:缺失值填充前后的变量对应列表
Name框:存储填补序列的新变量名称
Method下拉列表:可供选择的序列填充方法
² Series mean:全体序列的均数,默认值
² Mean of nearby points:相邻若干点的均数,在下方的Span of nearby points单选框组中设置使用的相邻点数。
² Median of nearby points:相邻若干点的中位数,在下方的Span of nearby points单选框中设置使用的相邻点数
² Linear interpolation:线性内插,即缺失值相邻两点的均数,但如果缺失值是在序列的最前/最后,则无法被填充。
² Linear trend at point:该点的线性趋势,将记录号作为自变量,序列值作为因变量进行回归,求得该点的估计值。
Span of nearby points单选框组:设置相应填充方法中需要使用的相邻记录数。
Change:将所做得设定应用于相应变量
2.2时间变量的定义-Define dates过程
时间序列数据的一个明显的特点就是记录依时间排列。在SPSS中需要定义时间变量。只有在定义后,SPSS才承认该序列的诸如周期等时间特征。
例:美国1947年第一季度到1970年第四季度的GNP在gnp.sav文件中,其中只有一个变量gnp记录着各季度的GNP值,请根据提供的时间范围为其定义时间变量。
方法:对于这种时间序列数据,在数据输入时仅仅需要输入每个时间点上的具体数值,而时间变量应当用专门的过程来定义。在数据输入时即使直接输入时间变量,包括Season、Year,SPSS也不会自动认为它们是时间变量,从而无法进行时间序列分析。
采用Data | Define dates 过程来完成。

图2
下面对图2简单讲解如下:
Cases Are框:提供了各种时间的组合供用户选择。序列的周期由时间组合的最小时间单位决定,如Years,quarters的周期是4
First Case Is框组:要求输入第一个数据(该数据可以是缺失值)的时间,根据Cases Are框中的选择不同,相应的内容也会有所变动。右侧会显示相应等级的周期数
Current Dates栏:在界面左下角,定义好周期后,如果再次进入该对话框,则会显示当前数据的时间信息。
上述操作后,数据文件中将加入两个新产生的时间变量year_、quarter_,分别代表年、季度,另有一个变量date_,表示大致的日期(由于信息不全,只能是大致的日期,并且是字符串变量)
2.3时间序列的平稳化-Create Time Series过程
在时间变量定义完成后,时间序列就基本建成了。但是,并非随便建立一个序列就算万事大吉,时间序列分析都是建立在序列平稳的条件上的。一个平稳的随机序列过程有以下要求:均数不随时间变化;方差不随时间变化;自相关系数只与时间间隔有关,而与所处的时间无关。
实际上大多数的时间序列都是不平稳的。在做时间序列分析时,首先就是识别序列的平稳性,并且把不平稳的序列转化为平稳序列。
Create Time Series过程是SPSS用来对原始序列进行初步处理,以使序列达到平稳化的模块。它可以从原序列变量中通过差分、移动平均等变换同时计算一个或多个新序列,以帮助用户识别原序列的波动规律。
若时间序列的正态性或平稳性不够好,在需要进行数据变换。常用有差分变换(利用transform | Create Time Series)和对数变换(利用Transform | Compute)进行。
对时间序列进行平稳性检验的图检验方法有时序图检验和自相关图检验。
² 时序图检验:根据平稳时间序列均值、方差为常数的性质,平稳序列的时序图应该显示出该序列始终在一个常数值附近随机波动,而且波动的范围有界,无明显趋势及周期特征。
² 自相关图检验:平稳序列通常具有短期相关性。该性质用自相关系数来描述,就是随着延迟期数的增加,平稳序列的自相关系数会很快的衰减向零。(注:时间序列的自相关是指序列前后期数值之间的相关关系,对这种相关系数程度的测定是自相关系数)。如果在ACF图中,随着lag的增大,自相关系数不是迅速减少,则要考虑时间序列是否不平稳,是否有继续差分的必要。
例:前面已经为数据gnp.sav建立了时间变量,现在对该序列进行平稳化。
方法:时间序列分析的第一步一般先做一个观测值和时间的时序图。这对序列的整体印象和后面的分析都非常有帮助。
点击菜单Graph | Sequence,仅仅把gnp变量选择进入variable框中,把Year变量选择入横坐标的标签,别的设置保持默认,绘制时序图如下

从此时序图中可以看到很明显的线性趋势(序列图是稳步上升的)和周期性(每年的图形有相似性,每年的第四季度总是最高)。这是跟序列平稳的要求相悖的。所以,首先要把不平稳的序列转变为平稳的序列。1.方差平稳化:当序列的方差随着时间变化时,模型参数的点估计估计和预测也许不会出错,但是统计推断会有较大的影响。对数转换和平方根转换是使方差稳定的两种常用的方法,可以通过菜单项Transform | Compute进行。2.去除趋势:差分是去除趋势的有效办法,可以通过菜单项Transform | Create Time Series进行。
对序列进行上述处理后,再对新生成的变量做时序图,可以发现虽然序列还存在周期性(季节波动),但是趋势问题和方差不齐已经得到较好的解决。如果还希望去除季节波动,则可以对新生成的序列用季节差分Transform | Create Time Series的方法去除。
差分会带来一个问题,就是序列开始的数据减少。差分次数越多,减少的数据越多。如果过度差分会使还原到原始序列的难度加大,这是需要尽量避免的。
让上述时间序列平稳化的方法如下:
首先,Transform | Compute,对原始数据进行平方根转换。转换结束后在数据文件中新生成一列数据。然后对这新生成的一列数据,用Transform | Create Time Series进行差分。
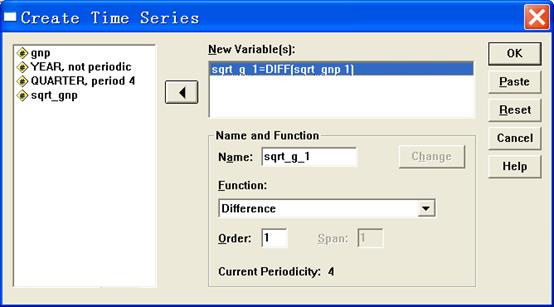
图3
主要对图3中的function下拉列表进行讲解,这是Create Time Series过程的核心。通过不同的计算方法可以得到相应的新序列。
² Difference:计算变量的一般差分(非季节性)。差分是序列平稳化时的常用手段,其作用是消除前后数据的依赖性。差分的次数可以在下方Order的框中指定。差分会损失数据,差分n次,则数据损失n个。
² Seasonal Difference:季节性差分。差分的间距由数据的周期决定。没有定义周期的数据不能做季节性差分。差分n次,数据损失季节的n倍。
² Centered moving average:中心移动平均,以当前值为中心,计算指定范围的均值。取移动平均的效果是把序列的噪声部分抵消,而把平滑部分保留。
² Prior moving average:前移动平均,计算当前值以前指定范围的数的均值。
² Running medians:移动中位数,计算当前值为中心,一定范围的中位数。
² Cumulative sum:累计和,以原序列的累积和为新序列
² Lag:滞后值,所谓滞后就是让原序列往后滞留指定的Order
² Lead:提前值,和滞后相反,让原序列提前指定的Order。
² Smoothing:计算原序列的T4253H平滑序列。
3.时间序列的图形化观察
时间序列有特有的图形观察工具,分别是:
² Sequence Chart:序列图,实际上是一种特殊的线图,但比一般的线图有更多适合时间序列特点的功能
² Autocorrelation Chart:做单个序列,任意滞后(包括负的滞后,也就是超前)的自相关和偏自相关图。ACF和PACF是描述单个时间序列的重要工具。
² Cross-Correlations Chart:交叉相关图,做两个或两个以上的时间序列,任意滞后的交叉相关图。互相关函数(Cross-correlation Function, CCF)是分析两个序列关系的有力工具。无论何时使用互相关函数来了解两个序列之关系时,必须确信两个序列是平稳的(即,每个序列的均值和方差在整个序列中大概一样)。原因是如果序列值随时间上升或下降,总可以把二者串起来,以至于即使两个序列毫不相关,但也显得高度相关。
² Spectral Chart:周期图和谱密度图,在谱分析时给出一个或多个序列的周期图和谱密度图。谱图和自相关图实质上是相同的,包含的是相同的信息,只不过表现形式不同。
后面的三种是专用的时间序列图,被统一放在了Graph | Time Series菜单中,它们对选择某些时间序列分析的统计模型的参数,以及对模型的残差评估尤其重要。
序列图在Graph | Sequence菜单项。
这些图形的一般界面中,有Variables框,用于选入要作图的序列变量,可以是多个序列。Time Axis Labels框:选入作为横轴标签的时间变量,如果缺失则用序号作为横轴单位。Transform框组:提供了一些时间序列分析中常用的变量变换方法,有自然对数变换、差分、季节差分三种,如果效果不好则需要用Create Time Series模块中的内容。下方的Current periodicity栏会显示当前序列的周期数。
自相关系数是序列和自身的提前或滞后序列间的相关系数。如果滞后为1,则是1阶自相关系数,滞后为2则为2阶自相关系数。自相关系数回答几个相邻数据的相关性。如果一阶自相关系数大,可以知道相邻时垫支存在较强相关性。二阶自相关系数大则说明相隔两个时点的值也密切相关。但是高阶的自相关是否真的非常重要呢?是它的确有意义,还是因为低阶自相关系数较大才引起高阶自相关系数也大呢?如果建立一个由以前值预测现在值的回归模型,需要包括多少个以前值?偏自相关函数(PACF)就是用于回答这个问题的。PACF是从高阶开始,逐个检验每阶的偏相关系数是否有意义,直到第一个有意义的为止。这时的阶数就是模型中应该包含的最大阶数。
Maximum Number of lags:指定需要计算自相关和偏相关的最大的滞后数lag。根据经验lag=20就够了,或者比该序列的最大周期大一些。
4.时间序列分析
4.1季节解构-Seasonal Decomposition过程
季节解构模块是用于分析有季节变化的时间序列的工具。它的基本思想是一个时间序列的信息可以来自四个方面:线性趋势、季节变化、循环变化和误差。而这四种信息可以通过乘法模型组合,也可以通过加法模型组合。根据模型结构的不同,季节解构分解信息的方法也不同。
季节解构模块要求序列无缺失值,或者已经用适当的方法弥补。
例:用美国1947年1月到1969年12月住宅建筑的数据nrc.sav为例,对序列nrc2进行季节解构分析
方法:选择菜单Analyze | Time Series | Seasonal Decomposition,如下图进行设置

图4
下面对图4中的设置做简单的介绍。
Variable框:选入需要分析的变量
Model单选框组:用于选择模型的种类,有两个选择:相乘模型(Multiplicative)和相加模型(Additive)。
Moving Average Weight单选框组:决定计算移动平均数的方法
² All point equal:以季节因素的长度为长度计算均数,所有的记录权重一样。当周期长度为奇数时多选。
² Endpoint weighted by 0.5:以周期长度+1作为长度计算移动均数。两端的数的权重取0.5,中间的权重都是1。当周期长度为偶数时多选。
Display casewise listing:要求输出计算的完整结果,包括计算的全部过程。
Output窗口中的部分输出结果如下:
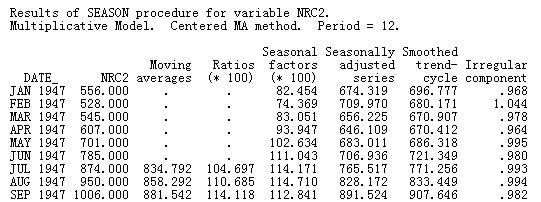
原序列经过以周期为长度的移动平均后得到的值已经去除了季节因素和误差,仅仅包含线性趋势、循环变化。所以上图的Ratios就是包含季节和误差的。(注意此模型为乘法模型)。求整个序列相同月份的Ratios的平均数并扣除误差成分就得到相应月份的季节因子(Seasonal factors)。其中误差是通过求各个月份Ratios的均数的均数得到的。然后原序列扣除季节因子就得到季节调整后的序列(Seasonal adjusted series)。最后还给出了平滑了循环因素的序列和不规则成分的大小。分析结果以新变量的形式加在数据文件后面,可以用于进一步的分析,比如做时序图。
4.2Exponential Smoothing过程
指数平滑法用序列过去值的加权均数来预测将来的值,并且给序列中近期的数据以较大的权重,远期的数据给以较小的权重。理由是随着时间的流逝,过去值的影响逐渐减小。指数平滑发只适合于影响随时间的消逝呈指数下降的数据。指数平滑法适用于呈水平发展的序列。对于上升的数据,预测总是偏低;下降的数据,预测总偏高。对于有上升或下降趋势的序列可以通过差分使序列平稳化,对于有季节变化的数据可以用季节差分处理。使用菜单Analyze | Time Series | Exponential Smoothing。最后SPSS会根据我们的操作,按照最优的原则将预测值和预测误差值存为新变量。据此就可以做出原始值和预测值的线图,进行比较。
例:数据文件sales.sav中存储的是某公司1992年1季度到2000年4季度的销售资料,请用指数平滑法分析预测将来4个季度,即2001年4个季度的销售额。
4.3ARIMA过程
ARMA模型-自回归滑动平均模型-是一族时间序列模型。是二十世纪70年代后应用最广泛的时间序列模型。两个特殊情况是自回归模型和滑动平均模型。
ARIMA模型建模的基本步骤可以分为4步:
² 序列的平稳性:使原序列满足ARMA模型平稳可逆的要求
² 模型识别:主要是通过读ACF、PACF和CCF把握模型的大致方向,为目标序列定阶,提供几个粗模型以便进一步分析完善
² 参数估计和模型诊断:参数估计是对识别阶段提供的粗模型参数估计并假设检验,做模型的诊断。
² 预测:这是模型实际应用价值的体现
模型识别和参数估计及模型诊断的过程往往是一个模型逐渐完善的过程,需要不断修正最初的选择。
ACF、PACF和CCF是描述序列特征的必备工具。仔细研究时间序列的相关情况是ARMA模型必经之路。在选择模型时根据就是ACF、PACF和CCF
八、实验结果和总结
实验结果以打印的实验报告为准。理解测验报告,总结实验过程,完成实验报告。
九、实验成绩评价标准
本实验采用五级评分制
A:能够熟练掌握软件,正确导出测评报告;实验报告内容完整、书写规范,能正确理解实验结果;
B:能够熟练掌握软件,正确导出测评报告;实验报告内容完整、书写比较规范,基本理解实验结果;
C:能够熟练掌握软件,正确导出测评报告;实验报告内容基本完整、书写基本规范,基本理解实验结果;
D:能够掌握软件,正确导出测评报告;实验报告内容基本完整、书写规范性较差,不能完全理解实验;
E:不能够掌握软件,不能正确导出测评报告;实验报告内容不完整、书写不规范,不能正确理解实验结果;