
 实验2:SPSS数据的录入、编辑、保存及合并
返回
实验2:SPSS数据的录入、编辑、保存及合并
返回
一、实验名称和性质
所属课程 | 社会科学SPSS统计分析软件 |
实验名称 | SPSS数据的录入、编辑、保存及合并 |
实验学时 | 6 |
实验性质 | 验证 |
必做/选做 | 必做 |
二、实验目的
掌握数据文件的建立与管理各个相关模块页面操作
三、实验的软硬件要求
硬件环境要求:
IBM兼容机;奔腾2.0GHz以上CPU;1GB内存以上;CD-ROM光驱(用来安装);
10GB硬盘空间
使用的软件名称、版本号以及模块:
SPSS20.0所有模块
四、知识准备
前期要求掌握的知识:
了解计算机基本知识,会使用windows操作系统。
实验相关理论或原理:无
五、实验材料和原始数据:详见随书附带光盘资料。
六、实验要求和注意事项:按照相关的操作流程逐一操作,不要漏掉某些关键指标。
七、实验步骤与内容
一切统计分析都是以数据为基础的,因此统计软件的数据管理能力非常重要。和传统的软件相似,spss中数据文件的管理功能基本上都集中在“File”菜单上。
在spss中,数据文件的编辑、整理等功能被集中在“Data”和“Transform”两个菜单项中。
掌握一些数据的整理、分类、变换和计算的方法。这些方法是进行数据分析的基础。有时我们可能要在数据分析前使用其中的一些方法,也有可能是在数据分析的过程中,也有可能是对数据的后处理。数据文件的整理主要是一些关于数据的排序、数据文件的行列转置,数据文件的合并分割,观测值的选择和加权等。数据的分类汇总本身就是一个统计方法。
在很多情况下,SPSS的分析过程往往对数据有特殊的要求,需要对数据文件进行进一步的加工,才能调用分析过程,对数据进行分析。
1.数据文件的整理
(1)观察值的排序
在进行数据处理时,有时需要按某个变量值重新排列各观测值在数据文件中出现的先后顺序。当建立或读入一个SPSS数据文件到数据窗口中后,可按下列步骤对数据文件中的观测值进行排序。
方法:打开Employee.sav,对工资等进行排序。点击菜单“Data”|“Sort Cases…”
![]()
![]()

图1
(2)数据文件的合并(个案合并和变量合并)
对于存在某种联系的两个数据文件,如果愿意,可以用SPSS的合并功能将它们按照一定的方式进行合并。SPSS提供了两种方式来合并数据文件中的数据:个案合并和变量合并。个案合并要求两个数据文件具有相同的变量,执行个案合并,相同变量所对应的个案集中到一个文件中去。变量合并要求两个数据文件具有相同的个案,执行变量合并,两个文件中相同个案对应的变量集中到新文件中。注意,增加变量时,外部文件与当前数据必须是升序排列文件。
(a)个案合并(使用Merge_1.sav和Merge_2.sav作为例子)
方法:点击菜单“Data”|“Merge Files”|“Add Cases…”

图2


图3
图3中,Unpaired variable显示非匹配变量。Variables in new Active Dataset显示将要形成新文件的变量。带有“*”符号的变量为工作数据文件中的变量,带有“+”符号的变量为外部数据文件中的变量。单击“Unpaired Variables”窗口中的变量名,再单击向右箭头按钮,可以把不匹配变量移到“Variables in new Active Dataset”窗口中去。
非匹配变量中如果有两个来自不同文件的变量,虽然它们的变量名不同,当数据的性质和意义相同,可以通过单击“Pair”按钮使这两个变量匹配,也就是这两个变量在最后新工作区的窗口中对应同一个变量。方法如下:在“Unpaired Variable”窗口中同时选中这两个来自不同文件的变量,这时“Pair”按钮变为可用,单击“Pair”按钮后,用“&”符号连接所选两变量名组成的新文件名显示在“Variables in new Active Dataset”窗口中,匹配实现。
Indicate case source as variable:指示观测值的变量选项。数值0表示源工作数据的观测值,数值1表示外部文件的观测值。选择该项后,也可以输入任一变量名做为指示观测值来源的变量。
(b)变量合并(使用Merge_3和Merge_4为例子)
方法:点击菜单“Data”|“Merge Files”|“Add Variables…”

图4
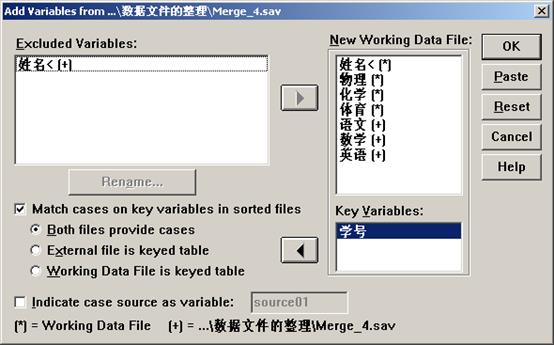
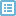
图5
下面对图5中涉及的一些参数设置进行简单介绍:
(1)“Excluded Variables”窗口内的变量在合并成的新文件中将不会出现;默认情况下,该窗口中显示外部数据文件中与工作数据文件中重名的变量。“New Working Data File”是新工作数据变量栏,窗口中的变量为建立新数据文件中即将用到的变量,其中是系统自动显示的变量,如果有不需要的,可以通过箭头将其移动到Excluded Variables栏。可以通过箭头,将变量在“Excluded Variables”窗口和“New Working Data File”窗口之间进行移动。
(2)“Match Case on Key Variables in sorted files”复选框,可以根据关键变量的值进行个案匹配。使用本项功能以前,需要将数据根据关键变量进行升序排列。
在“Match Case on Key Variables in sorted files”复选框下面的3个单选钮中选择一个,可以设置不同的个案匹配方式:
² “Both files provide cases”:SPSS默认选项。选择此项,表示对两个文件中的全部个案进行合并。如果两个文件中关键变量的值相等,则相应个案进行合并;如果值不等,则新文件中单独列出个案,如果对应于该个案变量缺失,则对应值缺失。
² “Working Data File is keyed table”:选择此项则以工作数据文件为基础,将外部文件中关键变量的值与工作文件中对应变量的值相等的个案合并到工作数据文件中。
² “External file is keyed table”:选择此项,是以外部文件的数据为基础,添加工作文件中关键变量的值与外部文件中对应变量值相等的个案到外部文件中。
另外需要注意的是,利用关键变量进行合并之前,必须先对数据文件中的数据根据关键变量进行排序。
(3)数据文件的拆分(使用car.sav为演示)
拆分与排序的区别:将数据进行拆分后,再对数据进行统计分析,输出的统计分析结果在显示时不同。
如果对数据基于一个或几个变量分类以后形成的各组数据的个体感兴趣,可以考虑用拆分(Split)。Split File拆分文件的功能是把当前工作分割成两个或两个以上的组,随后的分析将对每个组进行。所谓拆分,并不是要把文件真的分成几个,而是根据需要,依据某一个或几个变量按照一定顺序把原数据重新排列,把与所选定的一个或几个变量共同相关的数据在数据编辑器中集合到一起,以便集中操作和对比。
 方法:点击菜单“Data”|“Split File”
方法:点击菜单“Data”|“Split File”

![]()
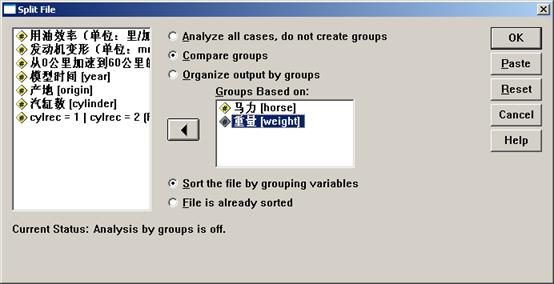
图6
下面就对图6中涉及的一些参数设置进行简单的介绍:
(1)Groups Based on:拆分变量存放栏。从变量表所选的变量是分组分析的依据变量。上图中,选择了horse和weight做为拆分变量。在有多个拆分变量的情况下,拆分变量的输入顺序对拆分结果有影响。上图中将horse做为第一拆分变量,weight做为第二拆分变量,SPSS首先根据horse变量所对应的不同数据对各个观测值进行拆分,然后对对应与相同horse值的weight变量的值进行拆分。拆分后原数据进行了重新排列,拆分变量取值相同的各个个案集中到了一起,这一点与排序有相似之处。实际上,对拆分后的数据进行处理,所得结果在查看器中的显示是不一样的。
(2)Analyze all cases, do not create groups:选择此项,将不对原数据文件进行拆分,而对所有数据进行统计分析。
Compare groups:选择此项,将根据所选分组变量的不同值对原数据文件进行分组,利用分组得到拆分数据。将对拆分数据所对应的分组单独进行统计,以便对各分组的特征进行更方便的比较。在结果输出表中,将把每一分组的统计结果集中在一个综合的表中,并为每个分组单独建立图形。
Organize output by groups:选择此项,将根据所选分组变量的不同值对原数据文件进行分组,利用分组得到拆分数据。将对拆分数据所对应的分组单独进行完整的统计分析,得到对应于每一分组的完整的统计结果(包括图(如果选择了有关选项的话)、表和文本)按分组变量组织输出选项,分组逐个显示分析结果。
选择Compare groups与Organize output by groups的区别在进行拆分的时候看不出结果的,只有在利用拆分的结果进行统计并输出统计的结果时,能看出区别。
注意:拆分数据前先要对原数据进行排序
(3)Sort the file by grouping variables:按分组变量对数据文件排序的选项,这是系统默认值,若选择,会自动根据分组变量进行排序,然后进行拆分。
File is already sorted:数据文件已排序的选项。选此项表示数据文件已按分组变量排序,系统不需要重做排序。
2.数据的选择(使用car.sav做例子)
我们通过试验或调查得到大量的原始数据,但有时候或者说大多数时候,对于特定的分析过程,只用到这些数据的一部分。下面介绍如何在大量的原始数据中选择我们需要的数据。
方法:点击菜单“Data”|“Select Cases”
![]()


图7
图7中的“Unselected Cases Are”区域中有三个选项用于选择被剔除数据的显示表达方式。
² “Filtered”表示在剔除个案的个案号上打一斜杆,表示这些个案在以后的统计分析中将不予以考虑。并会生成一列数据,用于表示哪些case被选中,哪些没有被选中
² “Deleted”表示没有被选择的个案将不在数据编辑器中显示。
根据上图“Select”方框中数据的选择方式不同,将SPSS提供的数据选择方式分为如下四种,下面进行详细介绍
(1)根据逻辑关系表达式选择数据
若在图7中单击“If condition is satisfied”,“If”按钮变为可用,单击该按钮,打开如下对话框,
在上面这个对话框中可以对条件进行设置,选择需要的数据,被剔除的数据会在工作表的个案号上划上斜杆,表示这些个案已经被过滤掉,在随后进行的统计分析中将不考虑这些个案的数据。上图中选择horse<200的个案对应的数据
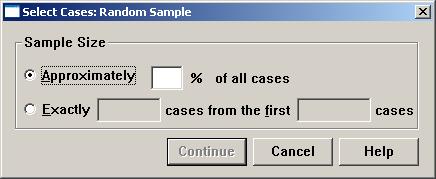
(2)随机选取数据
若在图7“Select Cases”对话框中,选择“Random sample of cases”单选按钮,“Sample…”按钮变为可用,单击打开“Random Sample”对话框,如下图所示
(3)在给定范围内选取数据
若在图7“Select Cases”对话框中选择“Based on time or case range”单选钮。“Range…”变为可用,单击该单选钮,显示“Range”对话框,如下图
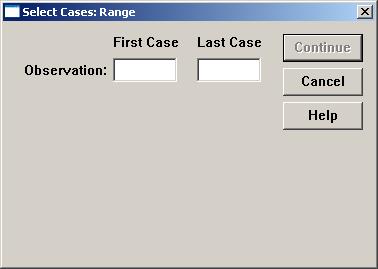
在“First Case”窗口中输入起始个案号,在“Last Case”窗口中输入最终个案号。选择以后,原数据文件中只保留个案号在“First Case”和“Last Case”之间的个案,其余个案均被滤掉。
(4)用过滤器变量选择数据
对应于某变量的值为0或缺失的个案,如果不打算对它们进行分析,可以将该变量选为过滤器变量,将该变量值为0或缺失的个案剔除。具体步骤如下:在图7的“Select Cases”对话框中选择“Use Filter Variable”单选钮,然后在左边窗口中的变量列表中选择一变量,单击向右箭头按钮,将该变量移到“Use Filter Variable”单选钮下面的窗口中,做为过滤器变量。

3.数据的分类汇总(数据的聚合)(用car.sav作为例子)
如果对数据基于一个或几个变量进行分类以后形成的各组数据的总体特征,如各国所产汽车的平均功率、最大功率等,或各国所产4缸、6缸或8缸汽车的平均功率(horse表示的是马力,也就是功率的单位)感兴趣,则可以考虑使用SPSS的聚合功能,使用聚合功能,可以获得按某个变量或某几个变量分组以后按照某种函数求得的新变量。
具体方法如下:
点击菜单 “Data”|“Aggregate”




![]()
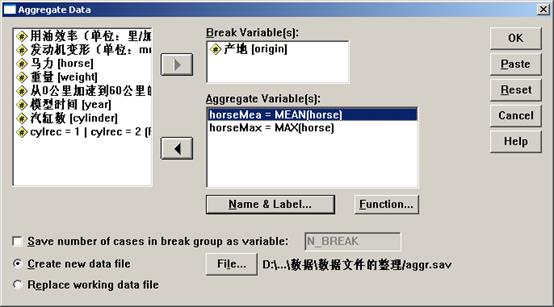
图8
图8为“Aggregate Data”对话框。在上面的对话框中的左边窗口中选择并单击一变量名,如origin,再单击右箭头按钮,将该变量名移到“Break”。可以有多个分类变量,本步操作使origin变量成为分类变量(Break Variable)。后续操作将按照分类变量中的不同值将其所对应的源变量(Source Variable)的值分成不同的组,然后进行函数处理,形成聚合变量(Aggregate Variable)。
在左边窗口中单击变量horse,单击窗口右侧下面的向右箭头按钮,“Aggregate Variables(s)”窗口中显示“horse_1=mean(horse)”。注意左边窗口中的horse变量名仍然还在,并没有移动到“Aggregate Variable(s)”窗口中。SPSS按照调用horse变量的次数和先后顺序给对horse变量聚合后得到的新变量命名为horse_1,horse_2等依次类推。这个名字可以更改,只需单击“Aggregate Data”对话框中的“Name & Label…”按钮,在弹出的对话框中进行修改就可以了。
单击“Aggregate Data”对话框中的“Function…”按钮,打开“Aggregate Function”对话框,该对话框用来确定聚合变量的具体内容,如图9所示,
![]()
![]()
![]()
![]()
![]()


图9
图9对话框中的聚合函数有3类,一类是对总体特征的描述,包括均值、总和等;第二类是对数据百分比的描述;第三类是对数据区间特征的描述。
还可以在“Break”窗口中输入多个分类变量,由多个变量共同决定聚合变量的内容。
八、实验结果和总结
实验结果以打印的实验报告为准。理解测验报告,总结实验过程,完成实验报告。
九、实验成绩评价标准
本实验采用五级评分制
A:能够熟练掌握软件,正确导出测评报告;实验报告内容完整、书写规范,能正确理解实验结果;
B:能够熟练掌握软件,正确导出测评报告;实验报告内容完整、书写比较规范,基本理解实验结果;
C:能够熟练掌握软件,正确导出测评报告;实验报告内容基本完整、书写基本规范,基本理解实验结果;
D:能够掌握软件,正确导出测评报告;实验报告内容基本完整、书写规范性较差,不能完全理解实验;
E:不能够掌握软件,不能正确导出测评报告;实验报告内容不完整、书写不规范,不能正确理解实验结果;